Vector Extended Soft Processor Architecture (VESPA)
A parameterized soft vector processor fully implemented on a DE3 FPGA board
The goal of this work is to encourage simpler software development over difficult hardware design by offering FPGA designers the option of scaling the performance of data parallel computations using a soft vector processor. Currently, FPGA designers implement their systems primarily in hardware using an HDL description, with a few least-critical computations and system control tasks implemented in C and executed on a soft processor such as Altera's Nios II or Xilinx's Microblaze. If these soft processors could scale their performance, they could be used to implement more critical computations hence reducing the amount of laborious hardware design necessary to implement a complete FPGA system. In the long term, our goal is to develop EDA tools for automatically generating soft processors that exploit both the properties in an application and the features in an FPGA.
To explore the feasibility of soft vector processor we have designed VESPA which implements a full soft vector processor and can execute industry-standard EEMBC benchmarks on the Altera DE3 board connected to a DDR2 memory. The VESPA processor is comprised of a MIPS scalar processor generated from SPREE and a hand-made vector coprocessor implementing most integer and fixed-point instructions from the VIRAM instruction set. VESPA's two key features are its scalability and flexibility.
Scalability
To lure FPGA designers into using a soft vector processor it must be able to effectively convert area into performance. Across a set of benchmarks, many from the EEMBC benchmark suite, we show that an FPGA designer can increase the number of vector lanes from 1 to 32 and achieve up to 27x speedup (average 15x) as seen in the figure below.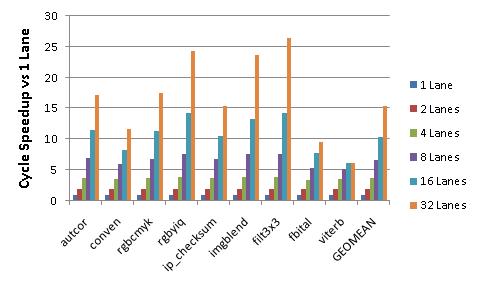
Flexibility
VESPA is highly parameterized allowing it to finely span a large design space. Its parameters allow a user to modify its compute architecture, instruction set, and memory system in several ways. A table listing its parameters are shown below.
| Parameter | Symbol | Value Range | |
| Compute | |||
| Vector Lanes | L | 1,2,4,8,16,... | |
| Memory Crossbar Lanes | M | 1,2,4,8,... L | |
| Multiplier Lanes | X | 1,2,4,8,... L | |
| Register File Banks | B | 1,2,4,... | |
| ALU per Bank | APB | true/false | |
| Instruction Set | |||
| Maximum Vector Length | MVL | 2,4,8,16,... | |
| Vector Lane Bit-Width | W | 1,2,3,4,..., 32 | |
| Enable Each Vector Instruction | - | on/off | |
| Memory | |||
| ICache Depth (KB) | ID | 4,8,... | |
| ICache Line Size (B) | IW | 16,32,64,... | |
| DCache Depth (KB) | DD | 4,8,... | |
| DCache Line Size (B) | DW | 16,32,64,... | |
| DCache Miss Prefetch (num cache lines) | DPK | 1,2,3,... | |
| Vector Miss Prefetch (num cache lines) | DPV | 1,2,3,... |
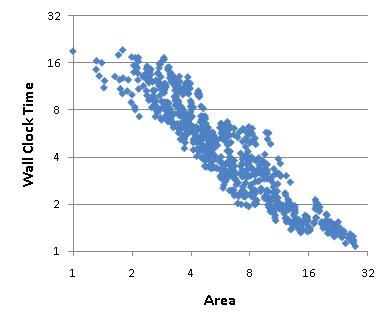
Combining all the above parameters results in an enormous design space. After pruning less interesting points, we explore the design space of 768 configurations as shown in the figure below. In terms of area, VESPA can span a range of 28x between the smallest and biggest configurations. In terms of wall clock time, the range is 18x between the fastest and slowest configurations.
People
Publications
- Peter Yiannacouras, J. Gregory Steffan, and Jonathan Rose, Fine-Grain Performance Scaling of Soft Vector Processors, International Conference on Compilers, Architecture and Synthesis for Embedded Systems (CASES), October 2009, Grenoble, France.
- Peter Yiannacouras, J. Gregory Steffan, and Jonathan Rose, Data Parallel FPGA Workloads: Software Versus Hardware, International Conference on Field-Programmable Logic and Application (FPL), Aug 2009, Prague, Czech Republic.
- Peter Yiannacouras, J. Gregory Steffan, and Jonathan Rose, Improving Memory Systems for Soft Vector Processors, Workshop on Soft Processor Systems (WoSPS - in conjunction with PACT), October 2008, Toronto, ON.
- Peter Yiannacouras, J. Gregory Steffan, and Jonathan Rose, VESPA: Portable, Scalable, and Flexible FPGA-Based Vector Processors, International Conference on Compilers, Architecture and Synthesis for Embedded Systems (CASES), October 2008, Atlanta, GA.
Links
Download
- Complete hardware design - Download here
- Gnu compiler with assembler ported for VIRAM - Download here
- Bones of simulator (unfortunately ours is based off a proprietary one) - Download here
- A few vectorized applications - Download here