
Greg Steffan Associate Professor & Jeffrey Skoll Chair in Software Engineering ECE, U of Toronto announce Professor Greg Steffan's passing on July 24, 2014.
|
Research:Computer Architecture, Compilers, Reconfigurable Computing, Distributed and Parallel Systems
Until recently we have been able to use the increasing hundreds of millions of transistors available on an integrated circuit chip to build ever more powerful processors capable of improving the performance of any program without extra effort from the programmer. However, we have recently reached limitations which leave only two possibilities for continuing to exploit increasing on-chip transistor resources: multicore processors, where multiple processors are incorporated on a single chip, and custom hardware accelerators, for example where a chip organized as a Field Programmable Gate Array (FPGA, a form of programmable integrated circuit) can be programmed to implement any form of hardware. For both multicores and FPGAs, the key to improving the performance of a single application is parallelism; however, to exploit parallelism requires that the programmer transform their programs: by introducing parallel threads and synchronization to target multicores, or by partitioning the software into hardware description language (HDL) to target FPGAs. The difficulty is that the vast majority of programmers are trained only in sequential programming, and do not understand the pitfalls of threaded programming or the subtleties of hardware design. The goal of this research program is to ease the extraction of parallelism from sequential programs so that non-expert programmers can exploit parallel hardware such as multicores and FPGAs, enabling the software industry and emerging applications to continue to enjoy dramatic improvements in computer system performance.
The following describes my ongoing and past research projects, along with representative papers for each.
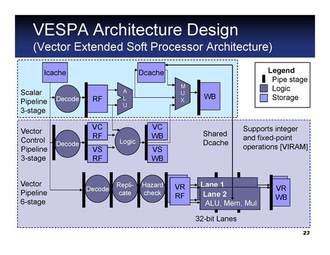
Overlay Architectures for FPGAs
Field-Programmable Gate Arrays (FPGAs) provide very low-risk access to VLSI technology compared to fully-fabricated chips, and faster time-to-market for products. However, the use of FPGAs has faced two increasingly daunting barriers: (i) the relative difficulty of designing hardware, which is typically done at the Register-Transfer-Level (RTL) in hardware description languages by specialized hardware engineers; and (ii) the large computational effort needed by the CAD tools to translate and optimize the RTL design for an FPGA, which can take up to a day for a large design.In this research we address these problems via overlay architectures: pre-designed soft structures for an FPGA that are themselves programmable, but more easily and more quickly. The simplest example of an overlay architecture is a "soft processor"---i.e., an instruction set processor built using the programmable logic of an FPGA. In our initial work we built the SPREE system, capable of generating soft uniprocessors with varying architectures and features. We have since developed several scalable, customizable, and easy-to-program overlays for different computing domains. Examples include soft multiprocessors for packet processing, soft vector processors, and we are working towards a GPU-like engine to support high-level languages for heterogeneous computing such as OpenCL.
 |
 |
 |
